Cet article est un des articles de la suite `Vision des ESBs par un architecte d’entreprise`.
Urbanisation
L’ESB s’inscrit au cœur de l’architecture globale du système d’Information de l’entreprise. Et dans ce cadre, il ne peut être vu comme un projet applicatif classique. Il doit être vu comme un projet transverse.
C’est pourquoi il est fréquent de rencontrer une démarche d’architecture d’entreprise accolée à un projet de mise en œuvre d’un ESB.
Un des objectifs d’une démarche d’architecture d’entreprise est d’aboutir à une architecture agile du système d’information. Cela passe par des étapes d’urbanisation, de cartographie fonctionnelle, d’îlotage applicatif, pour aboutir à la définition de processus d’entreprise.
Avec la définition de la spécification BPMN (Business Process Model Notation), 2006 pour la version 1.0 et surtout 2011 pour la version 2.0, les ESBs deviennent un support à l’exécution des processus d’entreprise. A ces fonctionnalités d’exécution est adjoint des fonctions de monitoring métier appelé BAM (Business Application Monitoring) qui permet d’avoir des métriques « fonctionnelles » et d’analyser l’efficacité de processus.
Avec ces démarches d’architecture d’entreprise et de BPM (Business Process Management), les ESBs orientés « flux » montrent leurs limites au profit de ceux orienté « services » plus agiles, car chaque consommateur de service est indépendant de son fournisseur, indépendant d’un point de vue « élection du endpoint », mais aussi d’un point de vue déploiement (consommateur et fournisseur sont dans des artefacts de déploiement indépendants).
BPM
Le terme « BPM » est très souvent associé au terme « processus ». Pour clarifier les discours, il est préférable d’utiliser les termes« workflow » et « orchestration » à la place de « processus ».
Workflow vs Orchestration
Les processus peuvent être groupés dans deux ensembles :
- les processus mettant en jeu des interactions humaines, généralement demandant une « validation » à un utilisateur. Ces processus sont appelés « workflow »,
- les processus complètement automatiques qui enchaînent diverses actions elles-mêmes réalisées par des machines. Ces processus sont appelés « orchestration ».
Les workflows nécessitent quelques fonctionnalités qui leur sont propres comme :
- la gestion de corbeille : ensemble des dossiers sur lesquels doit agir un utilisateur,
- affectation de tâches à un groupe d’utilisateur. Dès que la tache est prise par un utilisateur, elle n’est plus visible des autres,
- la délégation : capacité à déléguer une action à faire par un utilisateur à un autre utilisateur. C’est typiquement le cas lors d’utilisateurs absents (en congés). Pour ne pas retarder le traitement du dossier, il est automatiquement ou manuellement ré-affecté à un autre utilisateur,
- gestion des délais de réalisation des tâches humaines.
Orchestration
Compensation, la transaction de la SOA
Les processus de type « orchestration » mettent très souvent en jeu plusieurs ressources applicatives. Il n’est pas rare que, dans ce cas, une action effectuée sur une ressource applicative ne doit être réellement faite que si toutes les autres actions sur les autres ressources applicatives réussissent. Si une échoue, tout doit être annulé. C’est le principe du « commit » des bases de données.
Si dans le monde de la SOA, le concept de « transaction » existait, nous aurions alors à faire à une « transaction distribuée » à la façon XA1. Hors, les services doivent être sans état, donc pas de transaction possible, il faudra explicitement prévoir les annulations en cas d’erreur. C’est ce que l’on appelle la « compensation ».
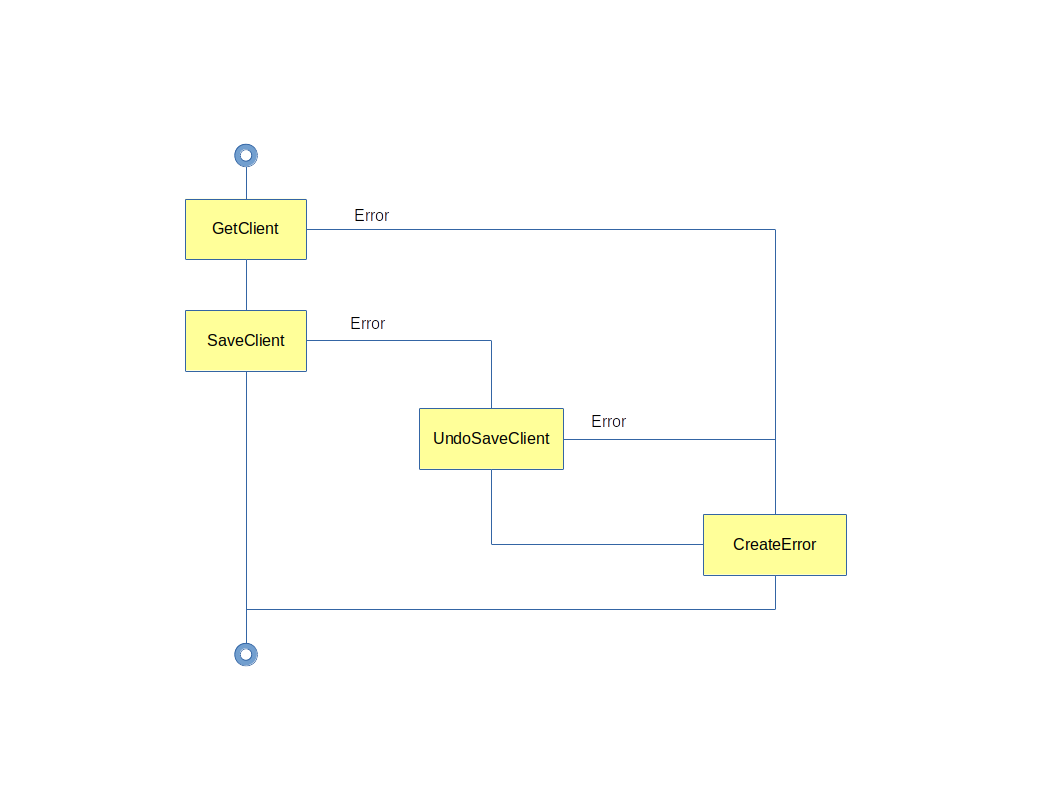
Checkpoint
Une orchestration, bien qu’automatique, peut prendre un certains temps pour être exécutée, notamment si une partie asynchrone intervient. Que ce passe-t-il si un crash logiciel se produit durant l’exécution d’une orchestration ?
Cela peut-être gênant de recommencer l’exécution depuis son début, en particulier si des services non-idempotents sont mis en œuvre. Il faudrait alors intégrer dans le processus des étapes pour savoir où reprendre le traitement. Ça ne va pas dans un sens de simplification, au contraire.
Par chance, il existe la notion de « checkpoint ». Un checkpoint est une étape du processus permettant de persister, par le moteur d’orchestration, l’état courant du processus. Ainsi, si un crash se produit, le processus pourra repartir depuis le dernier checkpoint exécuté. Uniquement les activités exécutées entre le moment du dernier checkpoint et le moment du crash seront perdues.
Attention, les opérations de checkpoint sont des opérations coûteuses en performance du fait de la persistance. Il faut en faire bon usage, et notamment ne pas en mettre partout. Un mix entre checkpoints et invocation de services idempotents est un bon compris.
Idempotence
« L’idempotence » est une caractéristique d’un service. Un service est dit « idempotent » si est seulement si toute invocation du service avec des paramètres identiques a les même effets sur le système. Autrement dit, le service a les mêmes effets qu’il soit invoqué une ou plusieurs fois. Par exemple, un service de rechercher est généralement idempotent.
L’idempotence est une caractéristique intéressante, car alors le service peut-être rejoué plusieurs fois sans réelle conséquence (il y a bien une conséquence sur les performances et volumétrie si l’on s ‘amuse à appeler plusieurs fois le service). Et notamment, dans le cas d’un crash se produisant durant l’exécution d’une orchestration utilisant des services idempotents, il n’est pas utile d’utiliser de checkpoint pour encadrer ces services, ils peuvent simplement être ré-exécutés. Les orchestrations seront alors d’autant plus performantes.
ESB et workflow
La mise en œuvre de workflows en liaison avec des services disponibles sur un ESB se fait par l’intégration d’un moteur de workflow, dans lesquels seront déployés les workflows, avec l’ESB.
Intégration d’un moteur de workflow externe
Une première intégration consiste à avoir le moteur de workflow à l’extérieur de l’ESB. Les services sont alors invoqués comme s’il s’agissait d’une application cliente standard :
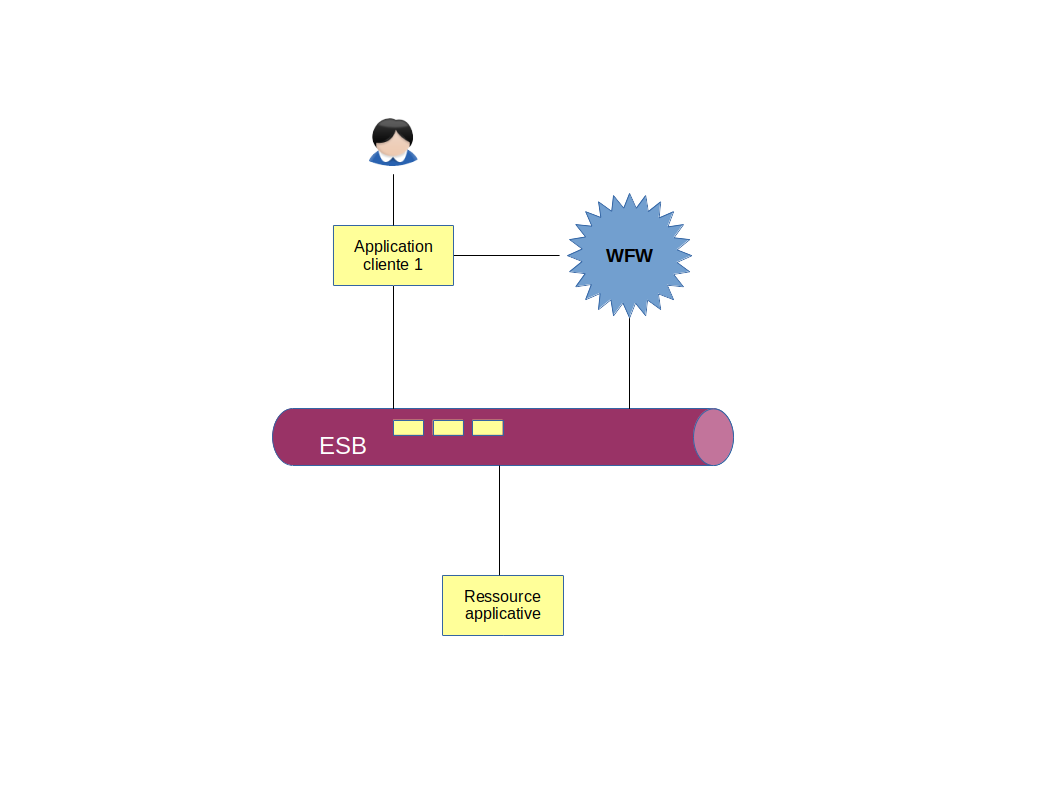
Cette solution n’est pas très agile, les applications clientes doivent interagir avec le moteur de workflow, donc doivent :
- connaître sa localisation,
- embarquer son API cliente pour faire avancer les étapes humaines.
Intégration d’un moteur de workflow via un service « technique »
Intégrer le moteur de workflow à l’intérieur de l’ESB permet de lever l’inconvénient d’agilité de la solution précédente.
Cette intégration consiste à créer un service encapsulant l’API du moteur de workflow. Il ne reste plus qu’à exposer ce service aux applications clientes. Ce service est plutôt technique dans le sens où il ne réalise pas d’opération à valeur ajoutée, mais reprend l’API du moteur de workflow.
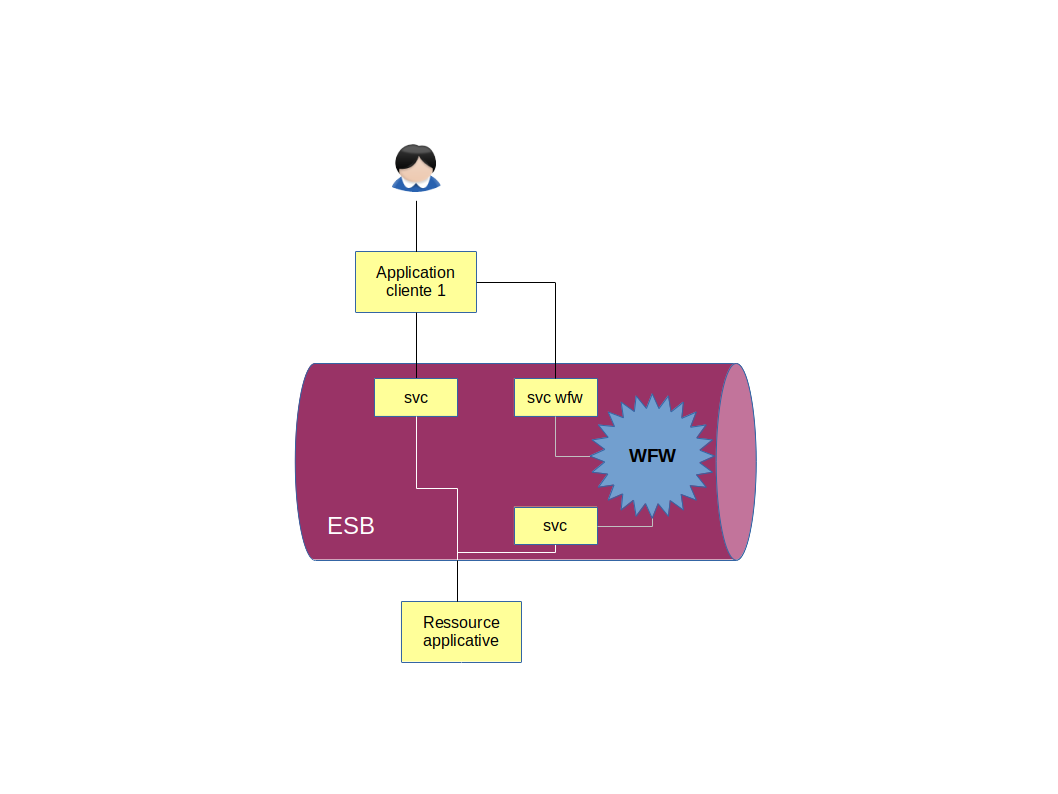
L’inconvénient de cette solution est plutôt de l’ordre conceptuel : les applications clientes invoquent un service technique.
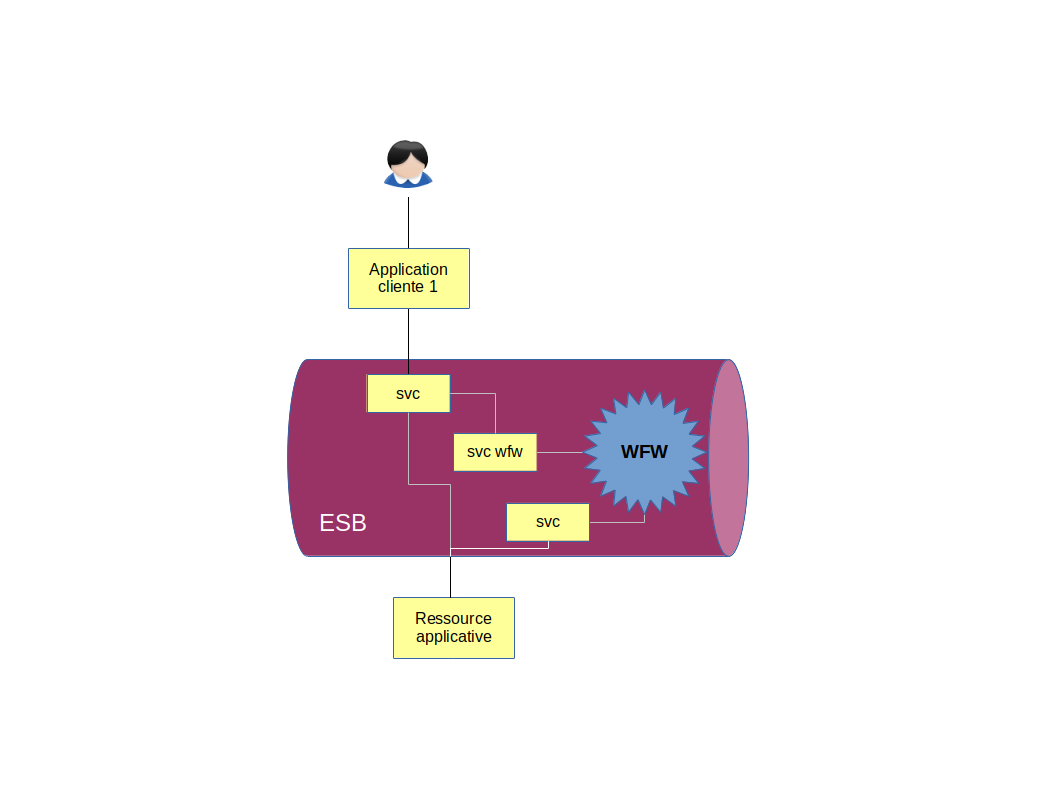
Intégration d’un moteur de workflow via un service « métier »
Une solution plus métier est de considérer les actions humaines comme des actions métiers.
Prenons l’exemple d’un assureur qui propose des contrats d’assurance habitation. Dans son processus métier, si la valeur d’une maison est supérieure à 300k€, des documents supplémentaires sont requis, ainsi que l’avis de risque d’un expert.
Dans ce workflow, on peut considérer l’action de l’expert comme une validation d’un contrat en précisant un risque. Ce qui peut se traduire sous la forme de l’opération « validerRisque(risque) » du service « Assurance Habitation ». Cette opération a en charge de débloquer l’instance de workflow, et de mettre à jour le risque sur la demande de contrat.
ESB et ETL
Les sytèmes ETL (Extraction, Transformation, Loading) sont souvent utilisés au travers de « batchs » pour synchroniser les données de différents systèmes. Dans ce paragraphe, on s’intéresse au lien entre les systèmes ETL et les ESBs.
Batch vs « fil de l’eau »
L’approche « intégration orientée services » a aussi pour objectif d’augmenter les aspects « temps réels » du SI, notamment en permettant les enchaînements de type « fil de l’eau ».
Un enchaînement « fil de l’eau » est un service orchestrant d’autres services de manière asynchrone. Une fois la requête envoyée au sous-service, et le « ack » reçu, le sous-service garanti à son consommateur que la requête sera traitée, et surtout quelle ne sera pas perdue. Le consommateur de service peut alors continuer son exécution, pendant que le sous-service s’exécute éventuellement en invoquant lui aussi d’autre service en fil de l’eau.
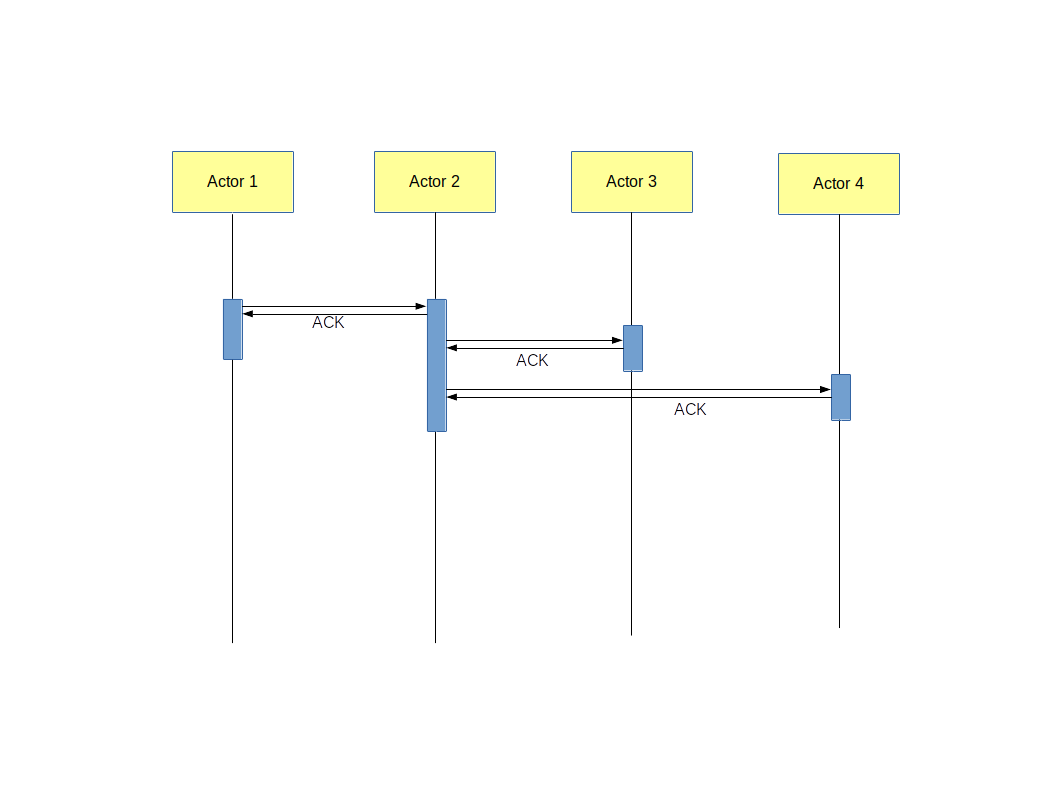
Les enchaînements « fil de l’eau » permettent de s’affranchir d’une intégration par « batch ». Donc à priori, les systèmes ETL n’ont plus lieu d’être.
C’est sans compter sur les échanges de données avec les partenaires de l’entreprise. Tous les partenaires d’une entreprise mettant en œuvre l’approche « service » ne sont pas au même niveau de maturité. Il reste alors encore des échanges sous la forme de fichier plat pour des traitements en masse. L’article àvenir sur les traitements par lots vous expliquera comment mettre en oeuvre ses traitements au mieux dans un ESB.
De l’enchaînement « fil de l’eau » au « processus »
Quand on y regarde de plus près, un enchaînement « fil de l’eau » est un enchaînement long de tâches, dont on ne veut pas attendre le résultat lors de son lancement. Ce qui correspond tout à fait à la notion de processus, mais avec le gros avantage d’avoir des appels de services synchrones qui rendent la gestion d’erreur plus simple.
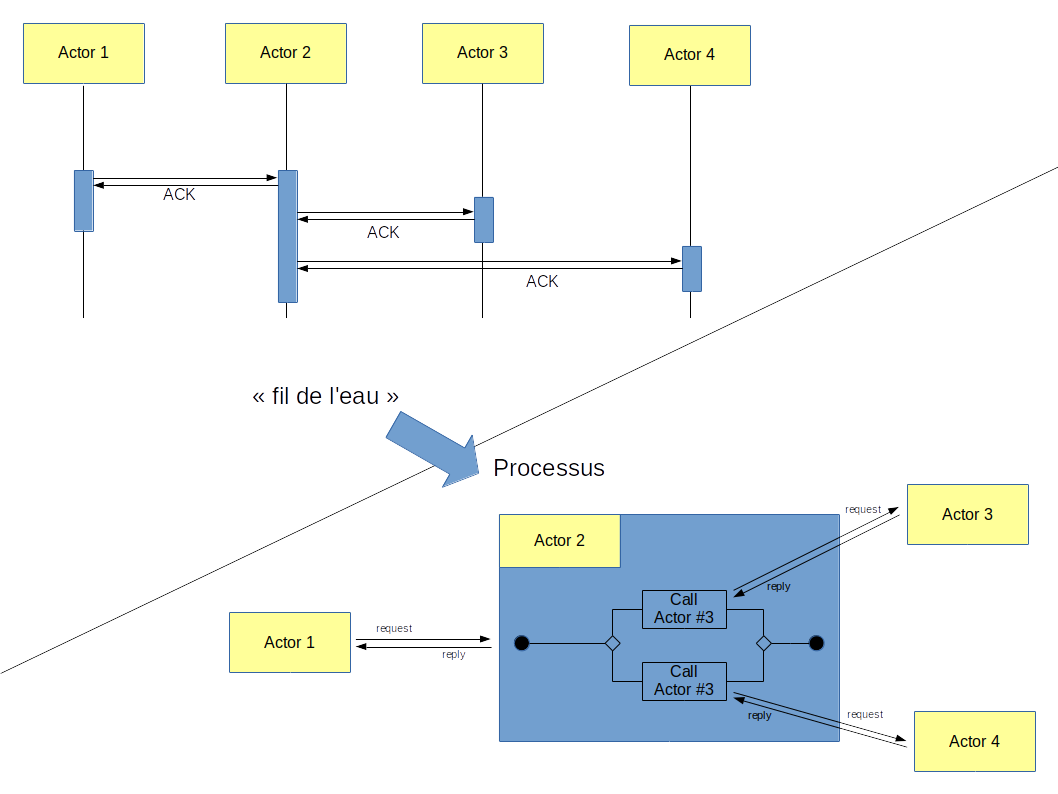
Finalement un enchaînement « fil de l’eau » se remplace avantageusement par un processus (plus précisément une orchestration) exécuté via un moteur de processus :
- un des avantages est une meilleure formalisation et une meilleure adéquation au métier de l’entreprise. En effet, la mise en place du processus nécessitera un minimum de modélisation, et ce d’autant plus que l’on utilisera du BPMN, et donc une réflexion métier, voir une participation des équipes « métiers » de l’entreprise. Les enchaînements « fil de l’eau » sont plus proches d’un simple développement, et restent alors très souvent cantonnés dans les équipes des développements,
- un autre avantage est le suivi des processus. Avec un enchaînement « fil de l’eau » il faut développer sa propre application de suivi, alors que c’est une fonction native du moteur d’exécution de processus avec en plus des fonctionnalités d’administration.