Dans le cadre d’une veille stratégique pour un de nos clients publics, nous avons étudié le sujet des outils de générations PDF. Il s’agit de produire des documents PDF respectant les normes d’accessibilité. L’article suivant constitue la 1ère partie sur les principales méthodes de conversion PDF.
1. Conversion XML avec XSL-FO
1.1 XSL-FO
XSL-FO (XSL-Formatting Objects) décrit la mise en forme des documents XML. Il fait partie des spécifications XSL (Extensible Stylesheet Language) qui est le langage de feuille de style associé au XML développé par le W3C (World Wide Web Consortium).
Le principe de base est que l’utilisateur écrit un document dans un langage XML comme le XHTML. Le composant XSLT transforme ensuite le document XML en XSL-FO. Ce dernier est enfin converti par un processeur de formatage FO en PDF.
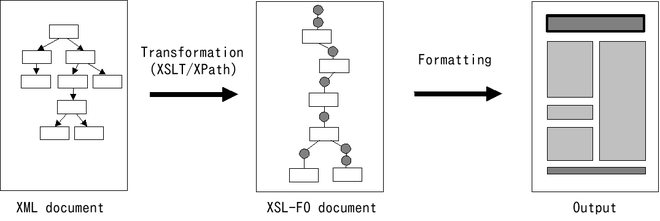
Illustration 1: Transformation d’un document XML en PDF via XSL-FO
Le XLS-FO est particulièrement adapté aux documents avec une typographie simplifiée comme les documents techniques, d’affaires, les factures, etc. Il ne convient pas pour faire des publications de haute qualité par exemple de type LaTeX.

Illustration 2: Exemple d’un fichier XML et les possibilité de rendu en PDF
Si XLS-FO est mature avec la publication de la version 1.1 en 2006, le langage est aujourd’hui arrêté avec la dissolution du groupe de travail en 2013. Il est aujourd’hui supplanté par le HTML/CSS qui fournit des fonctionnalités similaires.
Apache FOP est aujourd’hui la seule implémentation open source du XSL-FO. Nous allons l’étudier dans le paragraphe suivant.
1.2 FOP
Licence : Apache 2.0
Site Officiel : https://xmlgraphics.apache.org/fop/
Dernière version : 2.1 (01/2016)
Formatting Objects Processor (FOP ou Apache FOP) est un processeur de formatage qui permet de transformer un fichier XML contenant des éléments XSL-FO en pages. Le format PDF est le plus utilisé mais d’autres sont possibles. Il peut être exécuté sous forme d’une application en ligne de commande ou directement depuis l’application via l’API de la bibliothèque Java fournie.
FOP est développé à l’origine par James Tauber et donné à la fondation Apache en 1999. Il fait aujourd’hui partie de la suite XMLGraphics qui permet de convertir les fichiers XML en éléments graphiques avec Apache Batik dédié au SVG. Il est distribué sous licence Apache 2.0. La dernière version est la 2.1 datant de janvier 2016. Apache n’a pas encore implémenté l’ensemble des spécifications de la version 1.1 de XSL-FO. Le détail des implémentations est décrit sur le site officiel1. Un guide de démarrage rapide est disponible sur le site officiel2.
1.3 Accessibilité avec FOP
Le support du PDF/UA est une nouvelle fonctionnalité de la version 2.1 d’Apache FOP. L’accessibilité est gérée avec quelques limitations. Une partie du travail doit ainsi être réalisée par le rédacteur en particulier :
Les cellules de tableau doivent avoir une ligne de tableau comme parent ;
Les images doivent avoir une description textuelle (le texte au sein d’une image n’est pas accessible) ;
L’ordre des éléments dans le conteneur de blocs doit correspondre à l’ordre de lecture ;
La langue ne peut être spécifiée qu’au niveau de chaque page.
Concernant le marquage, FOP fournit un mappage par défaut des éléments de FO aux structures types définies par le standard PDF. Par exemple « P » est utilisé pour les paragraphes, « H1 » à « H6 » pour les titres, « L » pour les listes, « Div » pour les groupes d’éléments. Il convient de personnaliser le mappage pour améliorer l’exactitude des marquages.
Les seules limitations actuelles sont :
Il n’est pas possible de spécifier la forme étendue d’une abréviation ou d’un acronyme ;
Les haut et bas de page ne sont pas identifiés et sont lus à chaque changement de page.
Pour rendre le PDF compatible avec PDF/UA, il est nécessaire de donner un titre au document en ligne de commande et de bien activer l’option dans le fichier de configuration. Le site officiel d’Apache FOP fournit plus de détails sur la génération d’un PDF/UA3.
2 Conversion HTML avec CSS
La première approche pour convertir un HTML en PDF est de passer par le XSL-FO avec un outil comme HTML2Fo4. Il est cependant recommandé d’utiliser directement le XML source avec XSL-FO car le HTML/XHTML est une version tronquée du XML originale.
Une autre solution est de convertir les pages HTML via des feuilles de style CSS. Il existe plusieurs outils libres pour convertir HTML/CSS en PDF comme WkHTMLtoPDF, Weasyprint, Xhtml2pdf ou HTMLDoc. Cependant aucun parmi ceux étudiés ne supporte le marquage des documents PDF ou la norme PDF/UA. Cela peut s’expliquer par le fait qu’il n’y a pas un fort intérêt à exporter une page HTML en un PDF accessible alors que l’accessibilité Web existe déjà par le WCAG. En effet, une conversion HTML en PDF a généralement pour but de disposer d’un affichage fidèle pour faire des impressions papier.
Nous notons cependant qu’il y a de plus en plus une volonté de faire converger l’affichage pageWeb et et le format de document électronique. La demande est par exemple forte pour produire des livres électroniques avec une bonne qualité en utilisant les technologies Web. Un nouveau standard Web est en effet en train d’émerger pour les contenus imprimés : le CSS Paged Media.
Le CSS Paged Media définit un modèle de page pour afficher le contenu Web dans des dimensions fixes. Le W3C a publié en mars 2013 une version préliminaire du CSS Paged Media Module Level 3. En particulier, les spécifications fonctionnelles de base sont présentes comme le contrôle des marges, la taille et l’orientation de la page, les entêtes et la numérotation. Un brouillon de travail a également été publié en novembre 2015, signe que le développement de ce standard est très actif. Certains experts estiment même que le CSS Paged Media remplacerait à terme le XSL-FO laissé à l’abandon5.
On constate cependant qu’aujourd’hui les convertisseurs PDF intégrant le CSS Paged Media supportant le marquage PDF sont encore propriétaires : PDFReactor et AH 6.2/CSS Extensions. Dans le domaine du libre, le problème de l’accessibilité n’est pas encore résolu par le CSS Paged Media.
3. Conversion avec LibreOffice
3.1 Export PDF manuel
LibreOffice gère l’export des documents bureautiques au format PDF marqué en ajoutant la structure du document. Cette option doit cependant être activée dans les options.
Illustration 3: Fenêtre d’export PDF dans LibreOffice
Comme dit précédemment c’est au rédacteur de s’assurer que le document se conforme au PDF/UA notamment en ajoutant une description pour toute illustration et en utilisant les niveaux de titre et styles adaptés.
L’ensemble des procédés pour rendre accessible manuellement un document sous LibreOffice sont détaillés en français par le projet CAPA (Chaînes éditoriales avancées pour des documents pédagogiques accessibles)6.
Dans le cas où la génération d’un PDF se fait automatiquement, il convient de procéder de la manière suivante :
Créer un modèle de document et éditer de manière automatique via un API pour ODT comme ODF Toolkit ;
Exécuter une instance LibreOffice légère pour faire la conversion ODT vers PDF marqué en ligne de commande ou avec un outil automatique comme Uniconv
Nous allons détailler ces deux étapes par la suite.
3.2 ODF Toolkit
Licence : Apache v2
Site officiel : https://incubator.apache.org/odftoolkit/
Dernière version : 0.6.1 (06/2014)
ODF Toolkit est un ensemble de modules Java permettant de créer et manipuler par programmation des documents ODF. À l’inverse d’autres approches qui requièrent l’exécution d’un éditeur lourd via une interface automatisée, l’ODF Toolkit est une API légère qui convient à une utilisation en mode serveur. Si les fonctionnalités d’édition de base sont aujourd’hui remplies, il est important de noter que le projet est toujours en cours d’incubation au sein de la fondation Apache.
La boîte à outils est en réalité composée de quatre composants :
ODFDOM : API de bas niveau ;
Simple ODF (Simple API) : API de haut niveau ;
ODF Validator : pour s’assurer de la conformité d’un document au format ODF ;
ODF XSLT Runner : pour appliquer les feuilles de style XSLT aux flux XML du document.
Le module Simple ODF est le plus intéressant dans le contexte de la DGFiP. Il permet d’insérer du texte, des tableaux et des images en appliquant les styles requis pour l’accessibilité. Le site officiel contient une documentation riche7 et des exemples de code8 pour manipuler les documents via l’API. À noter qu’il est possible de créer manuellement un modèle de document ODF et ensuite d’utiliser Simple ODF pour faire de l’édition.
3.3 Export PDF automatique
3.3.1. LibreOffice en mode serveur
Il est possible ensuite d’exécuter LibreOffice en ligne de commande pour convertir un document ODT en PDF avec la syntaxe suivante :
libreoffice –headless –invisible –convert-to pdf:writer_pdf_Export fichier_origine –outdir fichier_destination
La documentation sur l’API de LibreOffice fournit l’ensemble des options concernant l’export de PDF9. Pour que l’option « UseTaggedPDF » soit prise en compte, il est nécessaire de modifier le fichier de configuration registrymodifications.xcu dans le répertoire de préférence LibreOffice de l’utilisateur (exemple : .config/libreoffice/4/user/). La ligne à ajouter est la suivante :
<item oor:path= »/org.openoffice.Office.Common/PDF/Export »><prop oor:name= »UseTaggedPDF » oor:op= »fuse »><value>true</value></prop></item>
Un moyen alternatif est d’utiliser l’outil Unoconv que nous allons décrire dans la partie suivante.
3.3.2. Unoconv (Universal Office Converter)
Licence : GPLv2
Site officiel : http://dag.wiee.rs/home-made/unoconv/
Dernière version : 0.7 (7/2015)
Unoconv est un outil en ligne de commande pour automatiser la conversion de documents et l’application des styles avec LibreOffice. L’installation d’une version de LibreOffice est un prérequis ainsi que le paquet Python Uno qui fait la connexion avec l’API de LibreOffice.
Unoconv peut lancer sa propre instance LibreOffice ou choisir une instance existante (listener en anglais) qui s’exécute sur la machine ou à distance. Les options d’export sont configurables directement. La ligne de commande à exécuter est la suivante :
unoconv -f pdf -e UseTaggedPDF=true fichier_origine
4 Remplissage d’un modèle PDF existant
Il est possible de créer un modèle compatible avec le PDF/UA qui soit rempli automatiquement avec les bibliothèques de génération présentées. Le remplissage automatique peut être facilité avec l’utilisation des champs de formulaire AcroForms ou Forms Data Format (FDF) qui sont supportés nativement par le standard PDF .
Dans la pratique, le remplissage d’un PDF existant n’est pas recommandé à cause d’un effort d’adaptation plus important, et ce pour plusieurs raisons :
Tout changement du PDF existant se fait manuellement et nécessite de bien maîtriser les spécifications du standard ;
Le PDF est souvent un document finalisé issu d’autres formats qui sont plus facilement et rapidement modifiables.
5 Synthèse
L’analyse de la présentation des méthodes de conversion PDF a permis d’identifier deux solutions solides pour générer des PDF accessibles dans le contexte de la DGFiP :
Apache FOP pour convertir des fichiers XML
LibreOffice pour convertir des documents bureautiques
Il convient cependant de noter la technologie XLS-FO sera sur le long terme dépassée par le CSS Paged Media sans qu’aujourd’hui la question de l’accessibilité soit résolue.